Argument Generation with Retrieval, Planning, and Realization
Xinyu Hua, Zhe Hu, and Lu Wang (ACL 2019)
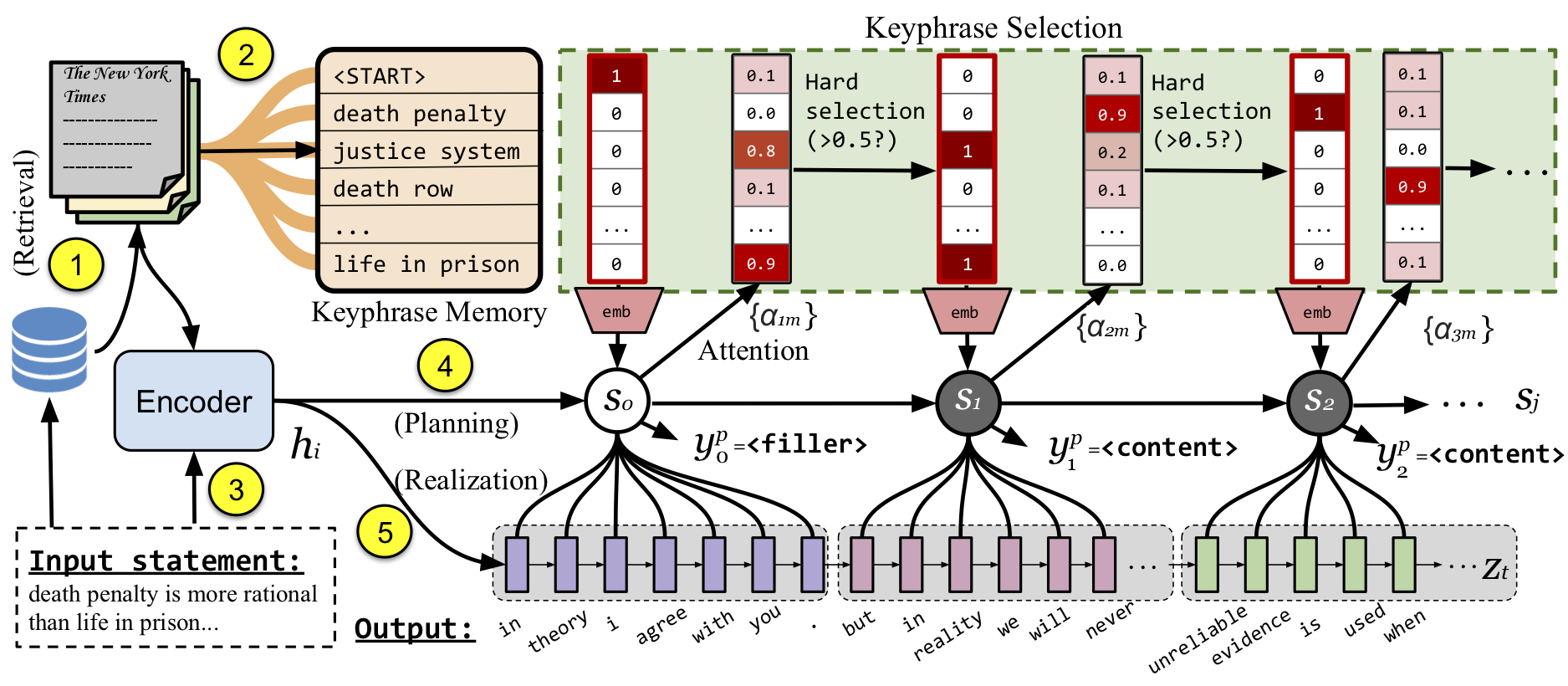
Abstract: Automatic argument generation is an appealing but challenging task. In this paper, we study the specific problem of counter-argument generation, and present a novel framework, CANDELA. It consists of a powerful retrieval system and a novel two-step generation model, where a text planning decoder first decides on the main talking points and a proper language style for each sentence, then a content realization decoder reflects the decisions and constructs an informative paragraph-level argument. Furthermore, our generation model is empowered by a retrieval system indexed with 12 million articles collected from Wikipedia and popular English news media, which provides access to high-quality content with diversity. Automatic evaluation on a large-scale dataset collected from Reddit shows that our model yields significantly higher BLEU, ROUGE, and METEOR scores than the state-of-the-art and non-trivial comparisons. Human evaluation further indicates that our system arguments are more appropriate for refutation and richer in content.